SOHO论文阅读
上一篇ViLBERT模型提出了使用two-stream的结构来分别处理图片和文本信息,然后再进行融合,在“vision-and-language”任务上还有其他模型使用了这种双流结构,因为其架构比单流结构更为复杂,所以架构的种类更加丰富,为了更深入地了解这种处理不同层次信息(图片和文本)的架构方式,我阅读了Seeing Out of tHe bOx:End-to-End Pre-training for Vision-Language Representation Learning这篇论文。特别地,这篇论文提出的视觉特征的提取方法也有其独到之处,能够不受目标特征局限性的影响。

论文地址和相关源码链接如下:
论文地址:https://arxiv.org/abs/2104.03135
相关源码:https://github.com/researchmm/soho
摘要
文章研究了用于视觉语言预训练的卷积神经网络和transformer的联合学习,旨在从数百万的图像-文本对中学习跨模态对齐,截止文章发表,最先进的方法是提取突出的图像区域并逐步将区域与文字对齐,但是由于提取出的图像区域仅仅代表图像的一部分,所以理解对应的自然语言是有难度的。文章提出了SOHO模型,将整个图像作为输入,并以端到端方式学习视觉语言的联合表示,SOHO模型不需要边界框标注,这使得其推理的速度比基于区域的方法块10倍。特别地,SOHO通过视觉字典(VD)学习提取全面而紧凑的图像特征,以促进跨模态的理解。最终,文章将SOHO模型在四个视觉语言任务上进行实验,并得到不错的性能和准确率提升。
介绍
最近跨模态学习的研究工作不断增加,特别是在视觉语言预训练(VLPT)领域。显而易见地,视觉表示在VLPT模型中起着重要作用,有一些模型利用了基于区域的图像特征并取得了不错的效果,这些特征是由在视觉基因组数据集上预训练的目标检测器提取出来的,但是这种方法也有一些缺点:
- 区域专注于边界框内的物体,而忽略了边界框外的上下文信息。这些信息对于区域与区域之间的关系理解和推理非常重要。文章以下图为例说明了这个事实,图中可以很容易地检测到男人、女人和船目标,但是如果缺少边框外的上下文信息,就会误以为人们在划船,从而导致模型在下游任务应用时的错误。

图1:模型在下游任务上的结果对比
- 对图像的视觉理解被限制在预先定义的区域类别中。
- 大多数区域特征是由检测模型提取的,存在质量低、噪声大、过采样等问题,并且依赖于大规模的box标注数据。
除了区域图像特征提取方法外,一些工作也研究了采用弱监督的目标检测的方法、或是通过基于网格的卷积特征来学习视觉表征的方法,但存在性能不高、只针对单个任务设计等问题。
为了克服基于区域的图像特征的局限性,更好地利用图像文本数据对进行跨模态理解,文章提出了一个端到端的视觉语言预训练框架SOHO,直接学习图像和文本的嵌入及其语义对齐。与现有的VLPT模型相比,SOHO采取了一个简单的管道,不需要复杂的视觉骨干进行预训练。相比于现有的基于区域的图像特征的方法,SOHO不需要标注类别或边界框,可以通过更广泛的图像-文本数据直接优化视觉表示来丰富视觉语义。
文章选择采用像素级的视觉表征,但像素级的视觉表征比语言的嵌入更加多样化和密集化,并且缺乏明确的监督,给对齐学习增加了难度。为了解决上述问题,文章引入了视觉字典,它代表了视觉领域中更全面和紧凑的语义。为了学习视觉字典,文中设计了一个移动平均编码器,将具有类似视觉语义的像素进行分组。
在预训练过程中,文章采用了Masked Vision Modeling (MVM) ,Masked Language Modeling(MLM),Image-Text Matching (ITM)三个任务来优化模型。
文章的贡献可以总结如下:
- 文章提出了SOHO模型,这是第一个直接用图像-文本对学习跨模态表示的端到端VLPT模型之一。在不需要提取边界框的情况下,模型可以实现至少10倍的推理速度。
- 为了更好地对齐图像和文本数据,我们提出了一个新的动态更新的视觉字典,它代表了图像中类似语义的视觉抽象。
- 对四个下游任务进行实验,得到了性能和准确率提升。
相关工作
Vision-Language中的视觉表示
早期的工作采用CNN分类模型来提取视觉特征,后来,Anderson等人提出了在视觉基因数据集上预训练的BUTD检测模型,以提取突出的区域特征作为视觉输入,最近,一些工作提出在特定的Vision-Language任务上,用卷积神经网络可以直接学习网格特征形式的视觉表征。
VideoBERT和bag of words文献也使用矢量量化来表示视觉信息。VD与相关作品的关键区别在于,我们用可训练的视觉编码器的输出动态更新基于VD的嵌入,而不是预先计算的输入特征(即VD是动态更新的)。VD的动态更新机制可以从视觉语言数据集中获取文本指导语义。因此,该模型可以直接用高级语义来优化视觉语言的理解和对齐。
Vision-Language的预训练
许多视觉语言预训练工作已经被提出用来学习跨模态表征,它们可以被分为single-stream模型和two-stream模型,双流模型分别处理视觉和语言信息,并在之后通过另一个transformer层将它们融合;相反,单流模型使用BERT来学习检测边界框特征(可以理解为ROI特征)和文本嵌入特征的双向联合分布。这两种类型都使用基于Transformer的模型来学习视觉-语言联合嵌入特征。虽然他们忽略了视觉表征学习对视觉-语言任务也很重要。
方法
SOHO是一个端到端的框架,它由一个基于CNN的可训练的视觉编码器、一个视觉字典嵌入模块和一个多层transformer组成,视觉编码器将图像作为输入并产生视觉特征,视觉字典嵌入模块被设计用来将不同的视觉语义信息聚集到视觉token中,transformer被用来融合视觉和语言模态的特征,并产生特定任务的输出。SOHO可以通过MVM、MLM和ITM任务进行端到端的预训练,并很容易地适应下游任务。SOHO的整体架构如下图所示,
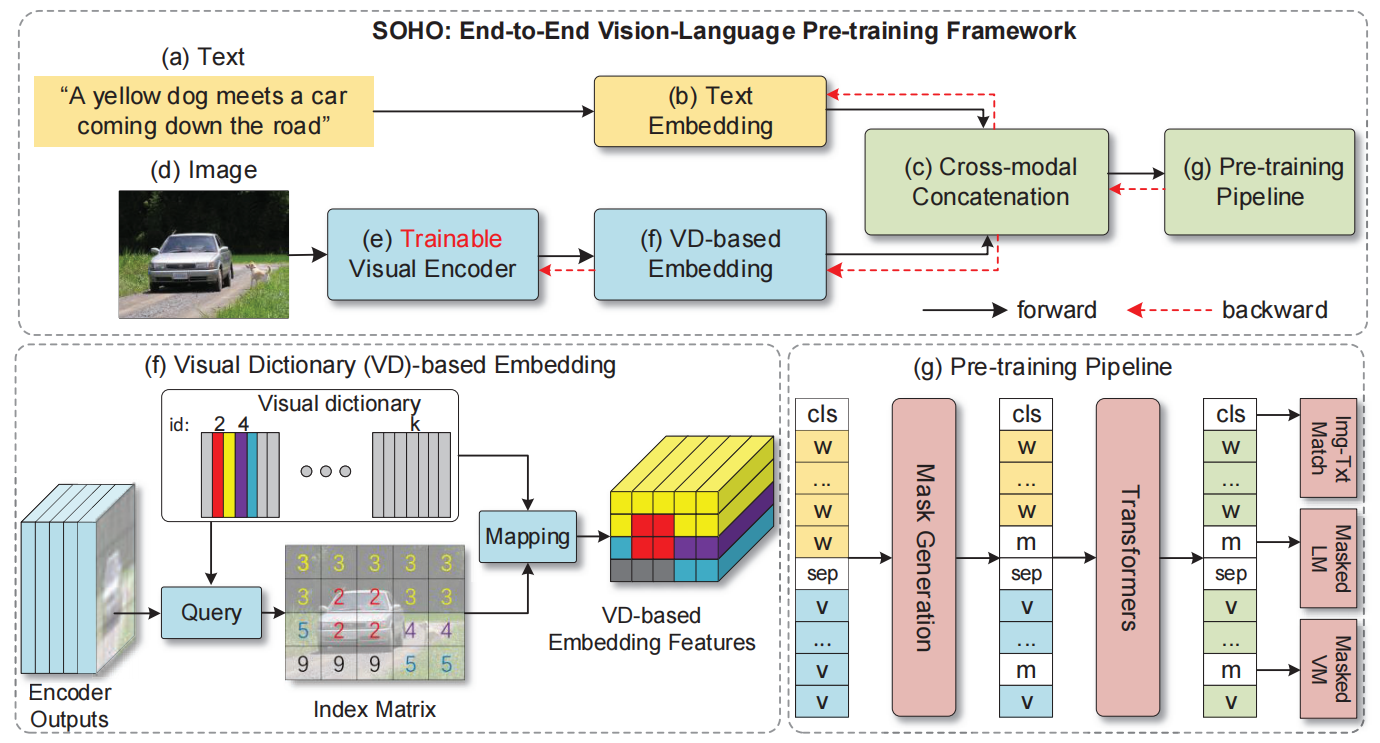
图2:SOHO模型架构
可训练的视觉编码器
基于区域的图像特征的表现能力受到预先定义的对象和属性类别的限制,并且不能学习到某些边界框外的上下文信息。为了保留所有视觉信息,文章建议使用一个可训练的CNN视觉编码器,将整个图像作为输入,产生图像级别的视觉特征,而不是区域级别的特征。由于不受边界框的限制,视觉编码器可以从预训练的损失函数或下游任务的损失函数中进行端到端的更新,进而进一步优化跨模态学习。给定一张图片\(\mathcal{I}\),可以根据以下公式得到其特征\(\mathcal{V}\),
\[ \mathcal{V}=E(\mathcal{I}, \theta) \in \mathbf{R}^{l \times c} \]
其中\(l\)表示嵌入特征向量的数量,\(c\)表示嵌入特征向量维度,另外,将在ImageNet上预训练的ResNet加上\(1 \times 1\)的卷积层和\(2 \times 2\)最大池化层作为编码器\(E\)的结构。
视觉字典
视觉特征编码器提取的视觉特征\(\mathcal{V}\)比语言词标记更加多样和密集,这将给跨模态理解的学习带来困难。为了弥补其与语言token的差距,我们提出了一个视觉字典,通过将相似的视觉语义聚合到同一图像特征中来标记视觉特征。
视觉字典嵌入
文章将视觉字典定义为一个矩阵\(\mathcal{D} \in \mathbf{R}^{k \times c}\),包含\(k\)个嵌入向量,每个\(c\)维,第\(j\)个嵌入向量被表示为\(d_{j}\),对于每一个视觉特征\(v_{i}\),文章通过在\(\mathcal{D}\)中搜索最近邻来计算其映射索引\(h_{i}\),记为如下公式,
\[ h_{i}=\operatorname{argmin}_{j}\left\|v_{i}-d_{j}\right\|_{2} \]
因此可以定义以下映射函数\(f\),将视觉特征\(v_{i}\)映射到视觉字典矩阵\(\mathcal{D}\):
\[ f\left(v_{i}\right)=d_{h_{i}} \]
其使用视觉字典中最近的嵌入向量来表示视觉特征,\(f^{-1}(j)\)表示逆映射函数,将索引\(j\)映射回一组视觉特征。
视觉字典的学习更新
视觉字典矩阵被随机初始化,并在一个小批次中通过移动平均操作进一步更新,记为如下公式,
\[ \hat{d}_{j}=\gamma * d_{j}+(1-\gamma) * \frac{\sum_{h_{i}=j} v_{i}}{\left|f^{-1}(j)\right|} \]
即保留一部分原有的\(d_{j}\),根据小批次中被归为\(h_{j}\)索引的视觉特征进行更新。
梯度反向传播
由于argmin操作时不可微的,梯度反向传播将被视觉字典停止,为了使视觉编码器可训练,采用了以下方法进行更新,
\[ f\left(v_{i}\right)=s g\left[d_{h_{i}}-v_{i}\right]+v_{i} \]
其中\(s g[\cdot]\)为停止梯度运算符。
视觉词典根据特征相似度对视觉特征图进行在线聚类,并通过聚类中心表示每个特征向量。具有相似语义的特征向量将被聚集到同一个聚类中,聚类的索引可以被视为一个虚拟的视觉语义标签。由于聚类可以受到视觉语言学习任务的影响,每个嵌入向量的学习语义更适合于跨模态的理解和对齐。
视觉字典面临着一个冷启动问题,直接将梯度从随机初始化的嵌入向量复制到视觉特征图上会导致不正确的模型优化方向(即模式崩溃)。因此,我们在前10个训练历时中冻结了视觉特征编码器中ResNet的参数。
预训练管道
文章应用多层transformer来学习融合视觉和语言特征的跨模态表征,为了学习视觉和语言相关任务的通用表征,文章采用自监督的方法,在一个大型的数据集上对模型进行预训练。除了通用的掩蔽语言建模和图像-文本匹配预训练任务外,文章还提出了一个新颖的基于视觉字典产生的虚拟视觉语义标签的掩蔽视觉建模预训练任务。
跨模态的transformer
对于视觉表示,文章利用正弦函数计算的二维位置嵌入来编码视觉token的空间信息,对于文本内容,按照输入BERT时的嵌入方法对其进行文本进行嵌入,最终将VD嵌入和文本嵌入连接起来形成输入序列,用于跨模态学习,需要特别注意的是,VD嵌入与文本嵌入的向量长度一致。
掩蔽语言建模(MLM)
掩蔽语言建模预训练任务鼓励模型构建语言token和可视化内容之间的映射关系,MLM的目标是根据其他词token\(\mathcal{W}_{\backslash i}\)和所有的图像特征\(f(\mathcal{V})\),通过最小化负对数似然来预测遮蔽的词token:
\[ \mathcal{L}_{\mathrm{MLM}}=-\mathbb{E}_{(\mathcal{W}, f(\mathcal{V})) \sim D} \log p\left(w_{i} \mid \mathcal{W}_{\backslash i}, f(\mathcal{V})\right) \]
掩蔽视觉建模(MVM)
文章提出了基于视觉字典的掩蔽视觉建模,在将图像特征输入到transformer之前,随机进行遮蔽,MVM的目标是根据周围图像的特征\(f(\mathcal{V})_{\backslash j}\)和所有的语言token\(W\),通过最小化负对数似然,预测被遮蔽图像的特征,
\[ \mathcal{L}_{\text {MVM }}=-\mathbb{E}_{(\mathcal{W}, f(\mathcal{V})) \sim D} \log p\left(f\left(v_{j}\right) \mid \mathcal{W}, f(\mathcal{V})_{\backslash j}\right) \]
需要特别注意的是,在视觉特征图中,相邻的特征可能有相似的值,因此共享相同的视觉字典映射索引,这将导致模型以一种懒惰的方式直接复制周围特征的标签作为预测值,为了防止这种情况的出现,在遮蔽阶段,文章首先在视觉字典中随机选择一个标签索引,然后将索引对应的所有视觉特征进行遮蔽。
图像-文本匹配(ITM)
为了增强跨模态匹配,文章采用图像文本匹配任务进行预训练,文章在[CLS]标签上应用二值分类器\(\phi(\cdot)\)来预测输入图像和文本是否匹配,ITM任务由以下的损失函数驱动:
\[ \mathcal{L}_{\mathrm{ITM}}=-\mathbb{E}_{(\mathcal{W}, f(\mathcal{V})) \sim D} \log p(y \mid \phi(\mathcal{W}, f(\mathcal{V}))) \]
视觉特征编码器、基于VD的图像嵌入模块和跨模态transformer可以进行端到端的联合训练,文章给三个预训练目标分配相同的损失权重,因此,SOHO的预训练目标如下所示,
\[ \mathcal{L}_{\text {Pre-training }}=\mathcal{L}_{\mathrm{MLM}}+\mathcal{L}_{\mathrm{MVM}}+\mathcal{L}_{\mathrm{ITM}} \]