ViLBERT论文阅读
BERT模型的提出使得大规模的预训练成为可能,与BERT模型仅仅处理文本模态不同,ViLBERT模型结合了图片和文本信息的特征,使用two-stream结构,基于大型的图像标题数据库训练与下游任务无关的通用模型,基于该模型通过少量调整即可实现通过标题检索图片、视觉问答等具体任务,最近在学习多模态特征有效的融合和对齐方法,于是对这篇文章进行了研读。

论文地址和相关源码链接如下,
论文地址:https://arxiv.org/pdf/1908.02265.pdf
相关源码:https://github.com/facebookresearch/vilbert-multi-task
摘要
ViLBERT模型是一个学习与任务无关的图像文本特征联合表示的模型,文章将流行的针对文本模态的BERT架构扩展到一个多模态的two-stream模型架构,在不同的流中处理视觉和文本输入,并通过共同注意的transformer层进行信息交互。文章通过自动收集的大型概念性标题数据集上定义两个代理任务,来对模型进行预训练,然后将其转移到多个既定的下游视觉和语言任务中,包括视觉问题回答、视觉常识推理、指代表达和基于标题的图像检索任务,在进行下游任务时只对基础架构做少量的补充。文章观察到,与现有的特定任务模型相比,在所有的四个下游任务上都实现了最先进的改进。文章认为,其工作代表了一种转变,即不再把学习视觉和语言之间的grounding作为任务训练的一部分,而是将visual grounding作为一种可预训练和可转移的能力。
PS: visual grounding涉及视觉和文本两个模态,输入是图片和对应的物体描述,输出是描述物体的box,与目标检测不同的是,输入多了语言信息,在对物体进行定位时,要先对语言模态的输入进行理解,并且和视觉模态的信息进行融合,最后利用得到的特征进行定位预测。
介绍
近年来,通过图像、视频等生成文本的研究已有了很多丰硕的成果,这些方法和任务可归结为“vision-and-language”。虽然这些任务都需要将自然语言和视觉特征结合,但是“vision-and-language”任务还没有一个统一的基础来提升这种结合能力。“vision-and-language”现在通常的做法是先分别预训练语言和视觉模型,然后通过任务进行基础知识的学习。通过这种方法学到的基础知识并不可靠,如果数据量不足或者是有bias的,那么模型的泛化能力会很差。
首先对模型进行预训练,然后再在目标任务上进行微调的手段已经被广泛使用,ViLBERT也采用了这种先预训练后转移的方案,并在预训练时尽可能地学习视觉和文本之间的关系。
为了学习这些联合的视觉-语言表征,我们借鉴了自监督学习方面的成功经验,这些成功通过训练模型来执行代理任务,从大量的无标签数据源中获取丰富的语义和结构信息,这些代理任务包括预测掩蔽词等等。为了通过类似的方法学习visual grounding,必须确定一个视觉和语言能够对齐的数据源来学习模态之间的关系,文章采用了概念性标题数据集。
文章提出了一个联合模型ViLBERT,用于从成对的视觉语言数据中学习与目标任务无关的visual grounding。文章的方法扩展了最近的BERT语言模型来共同推理文本和图像,关键技术创新是为视觉和语言处理引入单独的流,通过共同注意的transformer层进行信息交互,这种结构可以适应每种模态的不同处理需求,并在不同深度的模态之间提供互动,文章在实验中证明,two-stream结构优于single-stream结构。模型结构如下图所示,
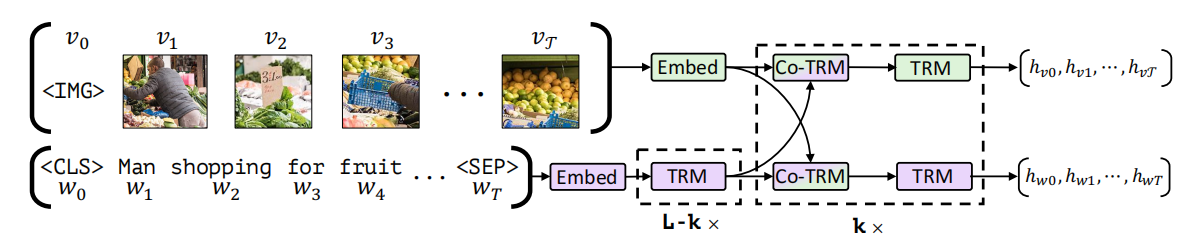
图1:ViLBERT模型结构
文章使用两种代理任务来训练模型:
- 遮蔽部分图片区域和文本单词,根据上下文内容预测被遮蔽部分。
- 预测文字和图片是否匹配。
将预训练模型作为基础,用于四个目标视觉语言任务,分别是视觉问题回答、视觉常识推理、指代表达和基于标题的图像检索。
方法
BERT
BERT模型时一个基于注意力机制的双向语言模型,当在大型语言语料库上进行预训练时,BERT已被证明对多种自然语言处理任务的迁移学习非常有效。
ViLBERT修改了BERT的键值注意机制,开发了一个多模态的共同注意transformer模块,通过在多头注意中交换键值对,这种结构使视觉注意到的文本特征被纳入到视觉表征中,同时将文本注意大的视觉特征纳入到文本表征中,BERT结构的标准transformer模块和ViLBERT结构的共同注意transformer模块对比图如下所示,
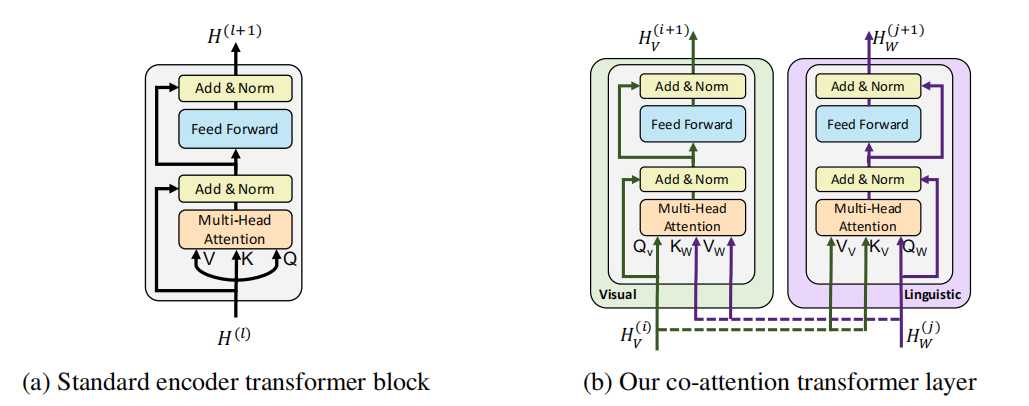
图2:标准transformer模块和共同注意transformer模块对比
下面简单地介绍BERT的输入文本表示和预训练任务。BERT的输入文本表示由三部分构成,分别是位置嵌入(position embedding)、段嵌入(segment embedding)和目标词嵌入(token embedding)。BERT的预训练任务包括掩蔽语言建模和下一句预测。具体的对于BERT模型的介绍可以参考原论文,传送门如下,
传送门:https://arxiv.org/pdf/1810.04805.pdf
ViLBERT:扩展BERT以联合表示图像和文本
受BERT模型在语言建模方面的成功启发,我们希望开发类似的模型和训练任务,从成对的数据中学习语言和视觉内容的联合表示,具体来说,文章考虑联合表示静态图像和相应的描述性文本。
文章首先叙述了一些直观的想法。可以首先将视觉输入的空间离散化,将这些视觉标记完全视为文本输入,并输入到预训练的BERT模型中,这种方法为single-stream方法。文章说明了single-stream方法的一些缺点:
- 最初的聚类可能会导致离散化错误,并失去重要的视觉细节。
- 以上方法对两种模态的输入进行了相同的处理,忽略了它们可能由于其固有的复杂性或其输入表征的初始抽象水平而需要不同的处理水平。
- 强迫预训练的权重去适应大量额外的视觉标记,可能会损害学到的BERT语言模型。
基于以上缺点,文章开发了一个two-stream架构,分别对每个模态进行建模,然后通过基于注意力的互动来融合它们,这种方法允许每个模态的网络深度不同,并能在不同的深度上实现跨模态连接。
如图1所示,ViLBERT学习的是静态图像及其对应描述文本的联合表征,分别对两种模态进行建模,然后通过一组基于注意力机制的信息交互将它们融合在一起。对每种模态都可使用不同深度的网络,并支持不同深度的跨模态交互。双流架构中的每个流都是由一系列的TRM(transformer block)和Co-TRM组成,可以观察到,流之间的信息交互被限制在特定层,文本特征需要先经过TRM模块处理才能进行信息交互,文章给出的解释是所选择的视觉特征已经相对高级,与句子中的单词相比,视觉特征需要有限的上下文聚合。
共同注意的transformer层
ViLBERT中引入了共同注意的transformer层,该模块为每个模态产生以其他模态为条件的注意力集合特征,实际上是在视觉流中执行以图像为条件的语言注意力,在语言流中执行以语言为条件的图像注意力。
图像表示
从预先训练好的物体检测网络中提取边界框和它们的视觉特征来生成图像区域特征,与文本中的文字不同,图像区域缺乏自然排序,文章采用一个5维的向量对区域进行位置编码,五个维度的元素分别为归一化后的bounding boxes的左上角和右下角的坐标以及图像区域覆盖占比,然后使用映射将位置编码与视觉特征维数匹配,进行相加后得到图像区域特征。使用一个特定的IMG token作为图像序列的开始,并用它的输出表征整个图像。
预训练任务
训练ViLBERT模型时采用了两个预训练任务,分别是掩蔽多模态建模和多模态对齐预测,如下图所示,
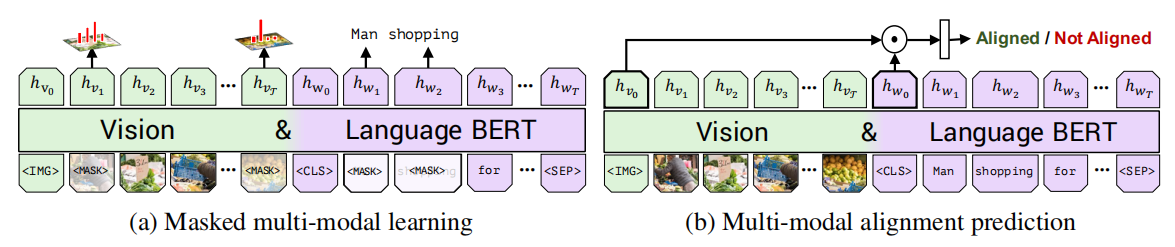
图3:ViLBERT预训练任务
掩蔽多模态建模任务来自于标准BERT中的掩蔽语言建模任务,屏蔽大约15%的单词和图像区域输入,并要求模型在剩余输入的情况下对屏蔽进行预测。在对图像进行掩蔽时,90%的概率是直接遮挡,另外10%的概率保持不变,文本的掩蔽方案与BERT一致。ViLBERT并不直接预测被掩蔽区域的图像区域特征值(原因:语言往往只能识别视觉内容的高级语义,而不太可能重建准确的图像特征),而是预测对应区域在语义类别上的分布(不预测位置信息),为了监督这一点,文章从用于特征提取的同一预训练检测模型中获取该区域的特征分布,训练模型以最小化这两个分布之间的KL散度。
多模态对齐预测任务必须预测图像和文本是否对齐,即文本是否描述了图像,文章把输出的\(h_{IMG}\)和\(h_{CLS}\)作为视觉和语言输入的整体表示,借用视觉和语言模型的另一个常见结构,文章将整体表征计算为\(h_{IMG}\)和\(h_{CLS}\)之间的元素乘积,并添加一个线性层来进行图像和文字是否对齐的二元预测。