Transformer综述论文阅读
最近想要研读一下关于transformer变体结构在多模态特征融合时的操作的论文,首先需要广泛地了解一下transformer结构及其变体,于是阅读了复旦大学邱锡鹏教授组里的transformer综述论文,本篇博客详细记录了综述论文中的重点以及本文作者对于这篇论文的理解。
介绍
Transformer结构在许多人工智能领域都取得了巨大成功,如自然语言处理、计算机视觉和音频处理领域,到目前,已经提出了大量Transformer结构的变体(又称X-formers),综述论文从三个角度介绍了各种X-former:X-former对于传统Transformer架构的修改、基于Transformer变体的预训练模型以及Transformer变体模型在领域上的应用。
Transformer结构最初是作为一个用于机器翻译的序列到序列模型提出的,后来的工作表明,基于Transformer的预训练模型(PTMs)可以在各种任务上达到最先进的性能。由于Transformer取得的成功,在过去几年内,又有人陆续提出Transformer的变体,主要是在以下几个角度作出改进:
- 模型效率。应用Transformer的一个关键挑战是它在处理长序列时效率低下,这主要是自注意模块中的计算和记忆复杂性导致的,改进方法包括轻量级注意力(如稀疏注意力变体)和采用递归和分层的注意力机制。
- 模型泛化。由于Transformer是一个灵活的架构,对输入数据的结构偏差几乎不作假设,所以很难在小规模的数据上进行训练,改进方法包括引入结构偏差或正则化,以及在大规模未标记数据上进行预训练。
- 模型适应性。这项工作的目的是使Transformer适应特定的下游任务和应用。
背景
传统Transformer
传统的Transformer是一个序列到序列的模型,由一个编码器和一个解码器组成,每个编码器是由\(L\)个相同的块堆叠而成。每个编码器块主要是由一个多头注意力模块和一个前馈神经网络组成,为了建立更深层次的模型,在每个块周围采用了残差连接,然后是层归一化操作。与编码器块相比,解码器块在多头自注意力模块和前馈神经网络这件额外插入交叉主义模块。
需要注意的是,与编码器中的自注意模块不同的是,解码器中的自注意模块被调整为每个位置防止关注后续位置。
传统Transformer的架构如下图所示,
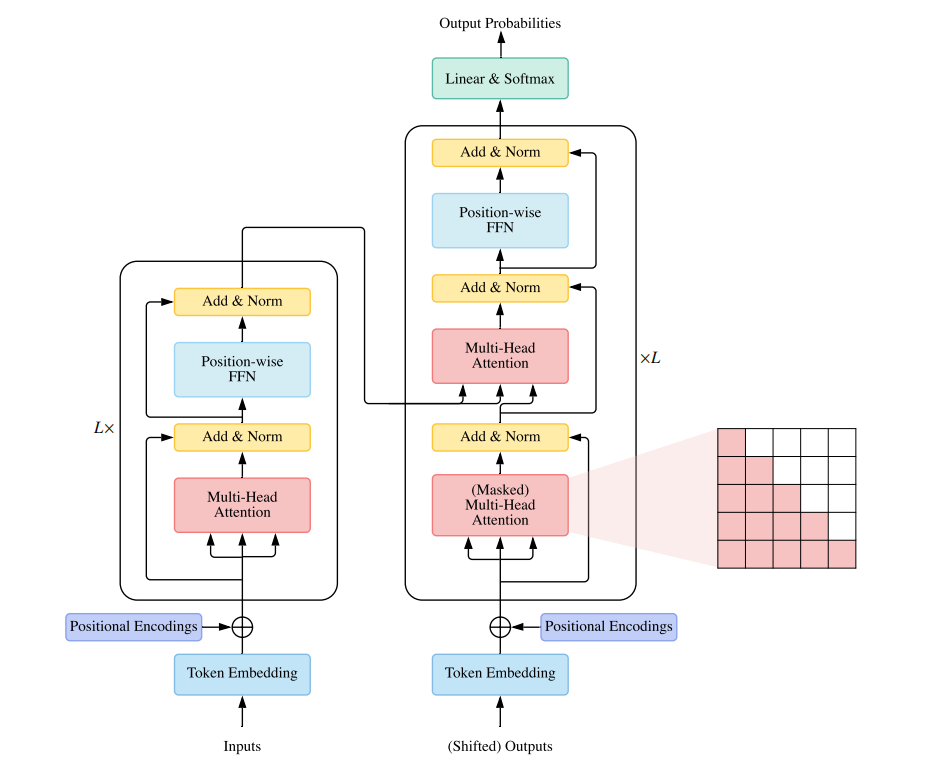
图1:传统Transformer架构图
注意力模块
Transformer的注意力机制采用QKV模型,计算公式如下,
\[ \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{\top}}{\sqrt{D_{k}}}\right) V=A V \]
在计算过程中需要注意QKV矩阵的维度,\(\mathbf{Q} \in \mathbb{R}^{N \times D_{k}}\),\(\mathrm{K} \in \mathbb{R}^{M \times D_{k}}\),\(\mathrm{V} \in \mathbb{R}^{M \times D_{v}}\),其中\(N\)和\(M\)代表queries和keys(values)的长度,\(D_{k}\)和\(D_{v}\)代表keys(queries)和values的维度,
1. softmax归一化操作按行进行
2. 点积缩放(除以\(\sqrt{D_{k}}\))减轻softmax函数的梯度消失问题
传统的Transformer模型采用多头注意力机制,将原本的\(D_{m}\)维度的queries、keys和values分别映射成\(D_{k}\)、\(D_{k}\)、\(D_{v}\)维,并使用\(H\)组学习的投影集。对于每一个投影的query、key和value,根据QKV模型计算公式计算输出,然后,将所有的输出连接起来,并将它们投射到\(D_{m}\)的维度表示,多头注意力机制计算公式如下,
\[ \begin{array}{r} \text { MultiHeadAttn }(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\text { Concat }\left(\text { head }_{1}, \cdots, \text { head }_{H}\right) \mathbf{W}^{O}, \\ \text { where head }_{i}=\text { Attention }\left(\mathbf{Q W}_{i}^{Q}, \mathbf{K W}_{i}^{K}, \mathbf{V W}_{i}^{V}\right) . \end{array} \]
在Transformer中,有三种注意力机制方式:
- 自注意力机制。在transformer的编码器中,设置\(Q=K=V=X\),其中\(X\)是上一层的输出。
- 掩码自注意力机制。在transformer解码器中,自注意是受限制的,即每个位置的查询只能注意到该位置之前的所有键值对。为了实现并行训练,通常对非标准化注意力矩阵\(\hat{A}=\exp \left(\frac{Q K^{\top}}{\sqrt{D_{k}}}\right)\)应用屏蔽函数,其中非法位置通过设置\(\hat{A}_{i j}=-\infty \text { if } i<j\)来进行实现。这种注意方式也被称为自回归注意或因果注意。
- 交叉注意机制。交叉注意记住的query是由前一个解码层的输出投影出来的,而key和value是由编码器的输出投影出来的。
position-wise前馈神经网络
在position-wise前馈神经网络中,参数在不同的位置上是共享的,因此position-wise前馈神经网络也可以理解为两个卷积层,核大小为1。
position-wise前馈神经网络的计算公式如下所示,
\[ \operatorname{FFN}\left(\mathbf{H}^{\prime}\right)=\operatorname{ReLU}\left(\mathbf{H}^{\prime} \mathbf{W}^{1}+\mathbf{b}^{1}\right) \mathbf{W}^{2}+\mathbf{b}^{2} \]
其中,\(\mathbf{H}^{\prime}\)是上一层输出,\(\mathbf{W}^{1} \in \mathbb{R}^{D_{m} \times D_{f}}, \mathbf{W}^{2} \in \mathbb{R}^{D_{f} \times D_{m}}, \mathbf{b}^{1} \in \mathbb{R}^{D_{f}}, \mathbf{b}^{2} \in \mathbb{R}^{D_{m}}\),需要额外注意的是,一般设置\({D_{f}}\)大于\({D_{m}}\)。
残差连接和标准化
为了建立一个深层次模型,transformer在每个模块周围采用了一个残差连接,然后进行层级标准化处理。例如,每一个transformer编码器模块可以表示为如下公式,
\[ \begin{aligned} \mathbf{H}^{\prime} &=\text { LayerNorm }(\text { SelfAttention }(\mathbf{X})+\mathbf{X}) \\ \mathbf{H} &=\text { LayerNorm }\left(\text { FFN }\left(\mathbf{H}^{\prime}\right)+\mathbf{H}^{\prime}\right) \end{aligned} \]
位置编码
由于transformer没有引入递归或卷积操作,因此对位置信息一无所知(尤其是对于编码器而言),因此需要额外的位置表示来模拟token的排序。
模型用途
- 使用编码器-解码器结构,通常用于序列到序列的建模。
- 只使用编码器结构,编码器的输出被用作输入序列的表示,通常用于分类或序列标记问题。
- 只使用解码器结构,其中编码器-解码器交叉注意模块也被移除,通常用于序列生成问题,如语言建模。
模型复杂度和参数量分析
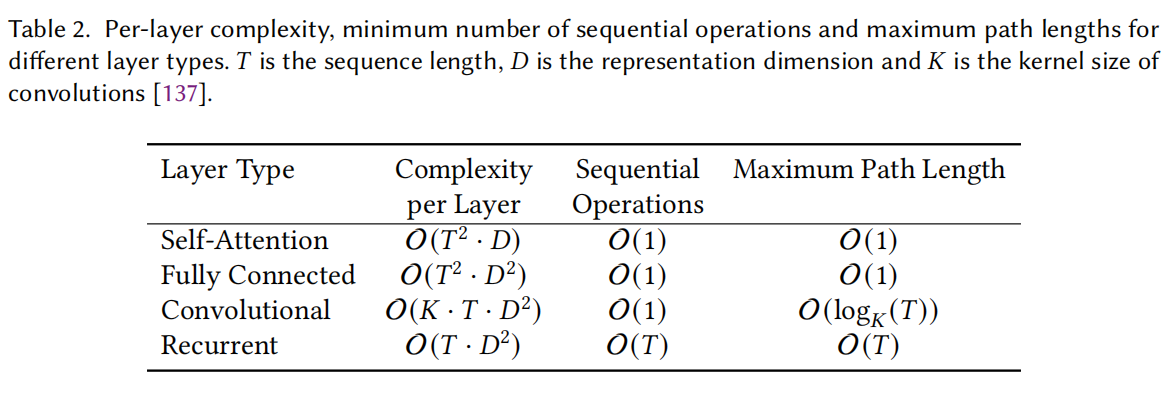
在假设序列长度为\(T\),维度为\(D\),FFN全连接层维度为\(4D\)的情况下,自注意模块和position-wise前馈神经网络模块的复杂度和参数量如下表所示,

对于transformer结构中自注意模块和前馈神经网络复杂度和参数量的推导,可以参考以下博客:
传送门1:https://0809zheng.github.io/2021/07/12/efficienttransformer.html 传送门2:https://zhuanlan.zhihu.com/p/264749298
transformer与其他模型的比较
对自注意操作的分析
- 它具有与全连接层相同的最大路径长度,使其适合于长距离的依赖关系建模,与全连接层相比,它的参数效率更高,在处理可变长度的输入时更加灵活。
- 由于卷积层的感受野有限,人们通常需要堆叠一个深度网络来拥有一个全局感受野,另一方面,恒定的最大路径长度使自注意能够以恒定的层数来模拟长距离的依赖关系。
- 相比于循环层,自注意的并行度更高,更擅长长距离建模。
下表展示了不同类型层的复杂度分析、最小序列操作数和最大路径长度。
关于归纳偏置
在机器学习中,很多学习算法经常会对学习的问题做一些关于目标函数的必要假设,称为归纳偏置 (Inductive Bias)
卷积网络通过共享的局部核函数施加了平移不变性和局部性的归纳偏置,循环神经网络通过其马尔科夫结构带来了时间不变性和位置性的归纳偏置,而transformer架构对数据的结构信息几乎不作假设,这使得transformer成为一个通用和灵活的架构,带来的副作用是容易对小规模的数据进行过度拟合。另外,transformer可以看作是一个带有完整有向图上所定义的GNN,其中每个输入都可视为图中的一个节点,然而,transformer和GNN之间的主要区别在于transformer没有引入关于如何构造输入数据的先验知识,transformer中的信息传递过程完全依赖于内容的相似性度量。
卷积网络的平移不变性体现在卷积核共享权重,局部性体现在卷积核大小是有限的;RNN的时间不变性体现在序列顺序中的每个时间步之间都是有关联的。
对transformer变体的分类
到目前为止,人们已经从三个方面改进传统的transformer模型:架构修改、预训练和应用,其中架构修改又分为模块级别的改进和体系级别的改进,下图给出了transformer变体分类说明,
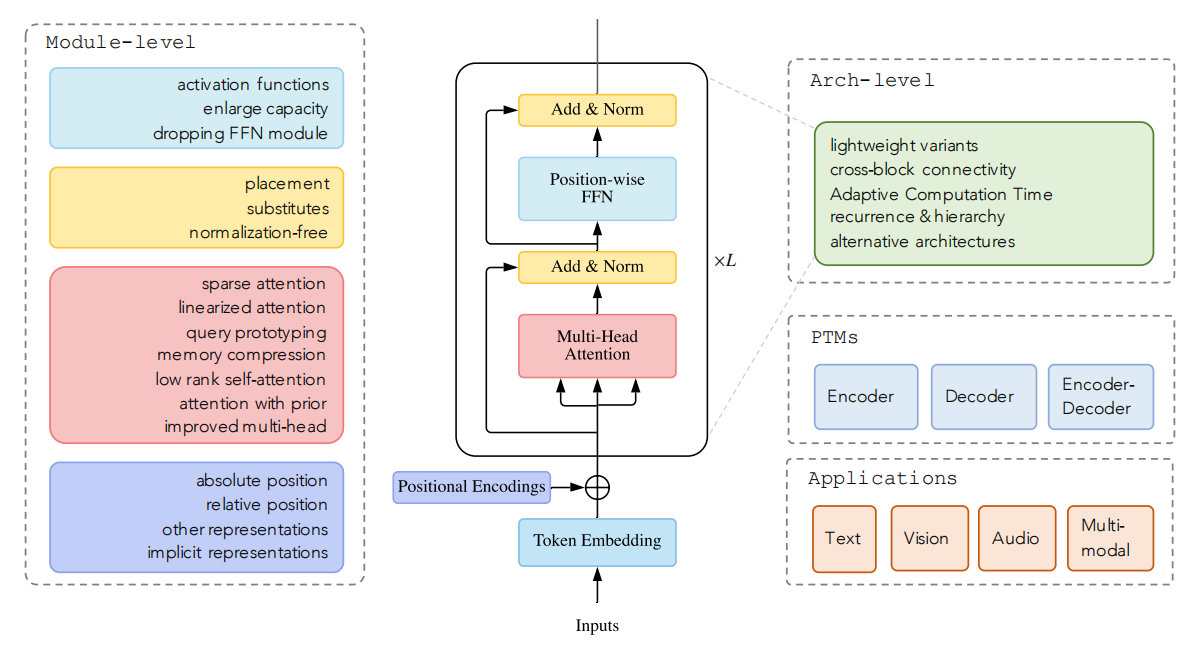
图2:Transformer变体分类
详细transformer变体分类如下图所示,
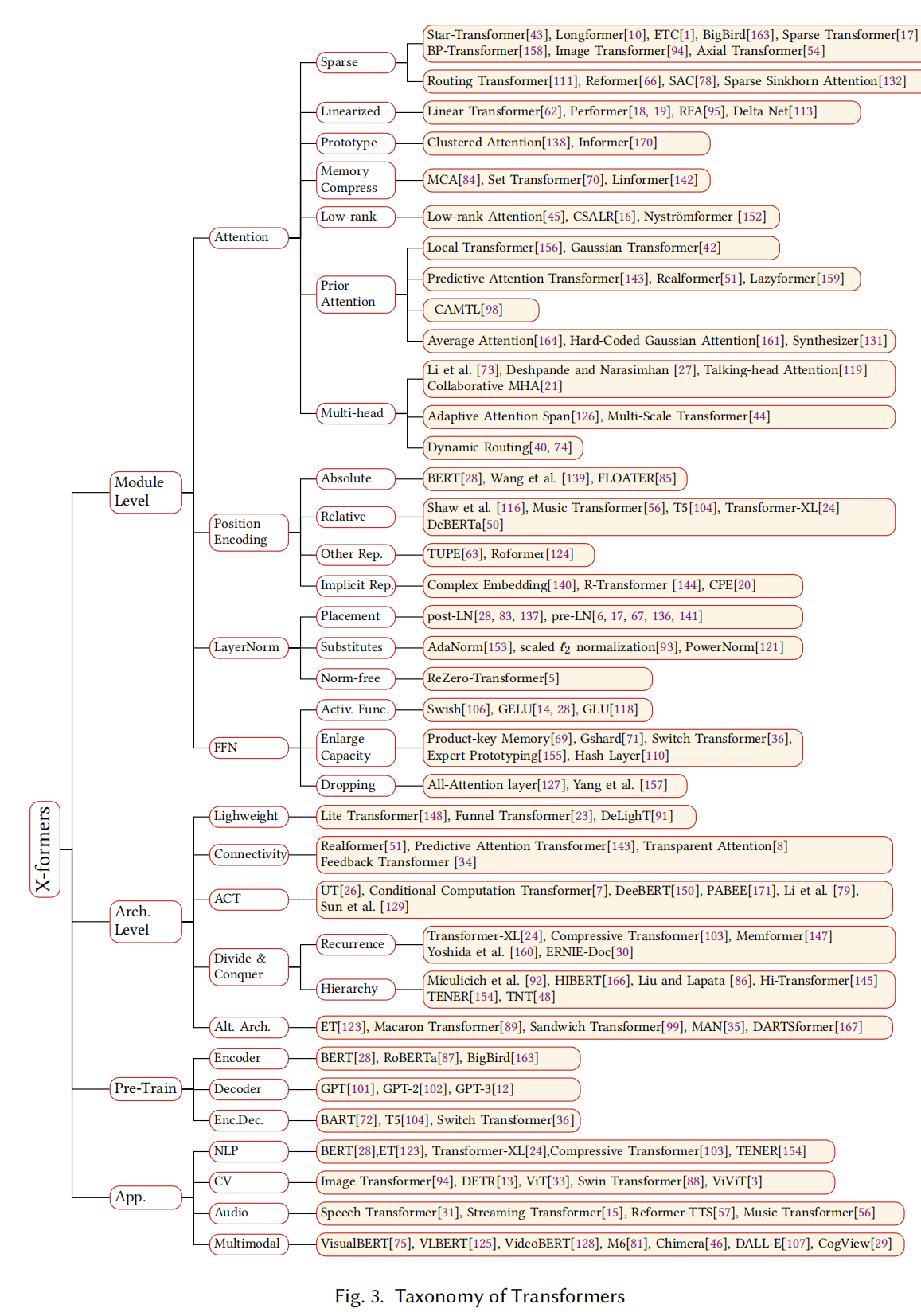
图3:详细Transformer变体分类
模块级别改进
attention机制
self-attention在实际应用中存在两大挑战:
- 复杂性。在处理长序列时,注意力模块称为瓶颈。
- 结构性先验。自注意对输入的数据不存在任何结构性偏向,甚至顺序信息也需要从训练数据中学习,因此,不含预训练的transformer在小规模或中等规模的数据上通常容易过拟合。
attention机制的改进方向:
- 稀疏注意力机制,将稀疏偏置引入到注意力计算。
- 线性化注意,将注意力矩阵和特征映射分离,降低至线性复杂度。
- 原型和显存压缩,减少了查询或键值对的数量,从而减小注意力矩阵大小。
- 低秩自注意,主要抓住自注意力的低秩性。
- 带有先验的注意力,主要使用先验注意力分布来补充或替代标准注意力。
- 改进的多头机制。
稀疏注意力机制
在标准的自注意机制中,每个token都需要注意其他所有token,但事实上,所学习到的注意力矩阵大多是非常稀疏的,因此,可以通过加入结构性偏差来限制每个query所关注的query-key对的数量,从而降低计算的复杂性。计算公式如下所示,
\[ \hat{\mathbf{A}}_{i j}=\left\{\begin{array}{ll} \mathbf{q}_{i} \mathbf{k}_{j}^{\top} & \text { if token } i \text { attends to token } j \\ -\infty & \text { if token } i \text { does not attend to token } j \end{array}\right. \]
根据确定稀疏连接的指标,可以将这些方法分为两类,基于位置的稀疏注意和基于内容的稀疏注意。
基于位置信息的稀疏化注意力
在基于位置信息的稀疏化注意力中,注意力矩阵是根据一些预先定义的模式来限制的,尽管这些稀疏模式有不同的形式,但有些可以分解为一些原子的稀疏模式,如下图所示,
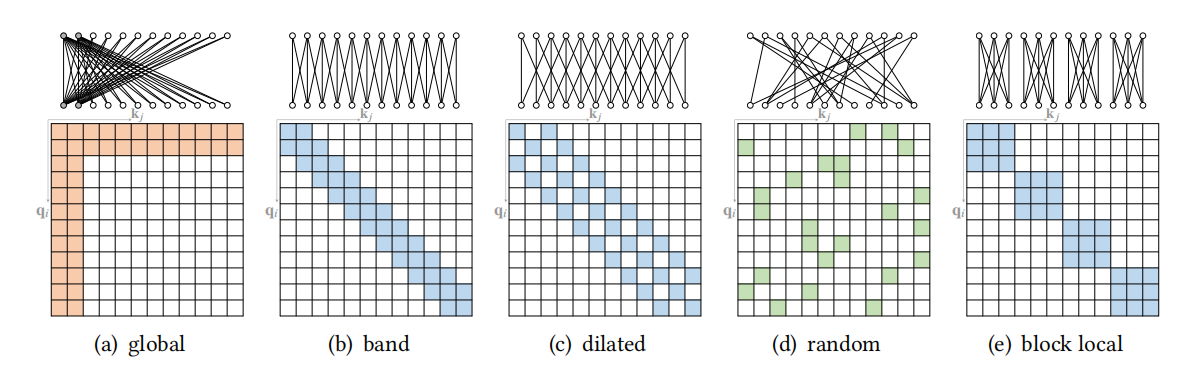
图4:原子稀疏注意力模式
- global attention:增加一些全局节点作为节点间信息传播的枢纽,这些全局节点可以注意序列中的所有节点,整个序列也注意这些全局节点。
- band attention:利用数据具有很强局部性的特点,限制了每个query对其邻居节点的关注。
- dilated attention:通过扩大扩张空隙来获得更大的感受野。
- random attention:为了提高非局部信息互动的能力,对每个query随机抽取几条边。
- block local attention:这类注意将输入序列分割成几个不重叠的query块,每个query块都与一个本地记忆块相关,一个query块中的所有query都只关注相应记忆块中的key,图4(e)描述了一种常见的情况,即记忆块与相应的query块是相同的。
下图展示一些复合稀疏注意力模式,复合稀疏注意力模式通常是原子稀疏注意力模式组合而成的,
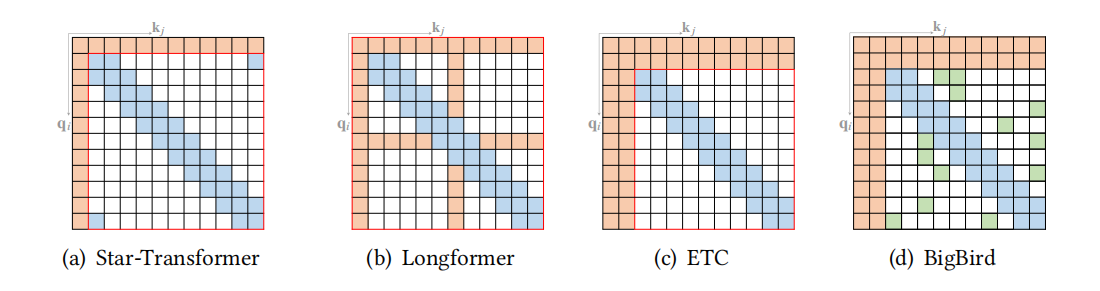
图5:复合稀疏注意力模式
除了上述模式外,一些现有的研究还探索了针对特定数据类型的扩展稀疏模式。对于文本数据,BP-Transformer构建了一个二叉树,其中所有的token是叶子节点,内部节点是包含许多token的跨度节点,是分层组织的;对于视觉数据,有Image Transformer和Axial Transformer。三种transformer变体的扩展稀疏注意力模式如下图所示,
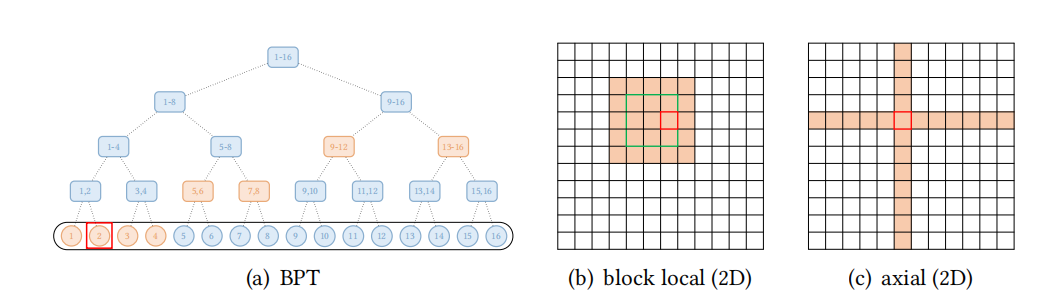
图6:扩展稀疏注意力模式
基于内容的稀疏注意力
构建基于内容的稀疏图的一个直接方法是选择那些可能与给定query有较大相似性分数的key。Routing Transformer使用K-means聚类算法,将query和key都集中在同一组中心点向量上,每个query只与其处在相同cluster下的key进行交互。Reformer采用LSH哈希方法来为每个query选择key-value,其主要思想是对query和key哈希,分到多个桶内,在同一个桶内的query、key参与交互。SAC将输入序列视为一个图,并学习构建注意力边,以使用自适应稀疏连接改善特定任务的性能,其中边预测器是通过强化学习来训练的。Sparse Sinkhorn Attention首先将query和key通过排序网络控制分为几个块,并为每个query块分配一个key块,每个query只允许关注被分配给其相应块中的key。
线性注意力
线性化注意力是一类用\(\phi(Q) \phi(K)^{\top}\)近似或替换非标准化注意力矩阵\(\exp \left(Q K^{\top}\right)\)的方法,其中\(\phi\)是按行方式应用的特征图,因此,非归一化注意力矩阵的计算可以通过计算\(\phi(Q)\left(\phi(K)^{\top} V\right)\)来线性化,如下图所示,
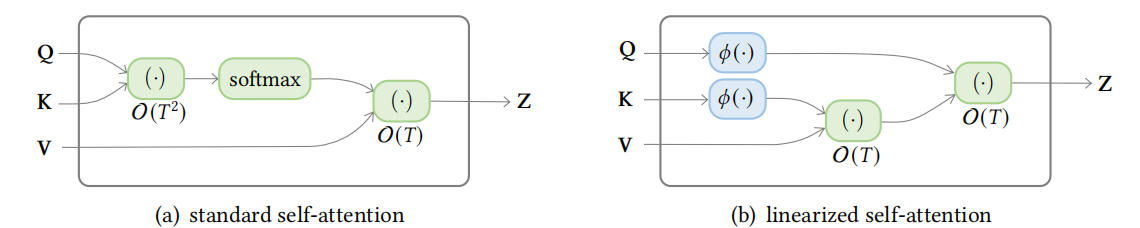
图7:标准注意力和线性注意力对比
该模型通过聚合(由特征映射的)key和value的外积表示的关联来维护内存矩阵,然后通过将内存矩阵与具有适当归一化的特征映射查询相乘来检索值,这种方法有两个关键组件,包括特征图和聚合规则。
查询原型和键值内存压缩
除了使用稀疏注意和基于内核的线性化注意,人们还可以通过减少查询(query)或键值对的数量来降低注意的复杂性。使用原型查询的注意力机制和压缩键值内存的注意力机制如下图所示:
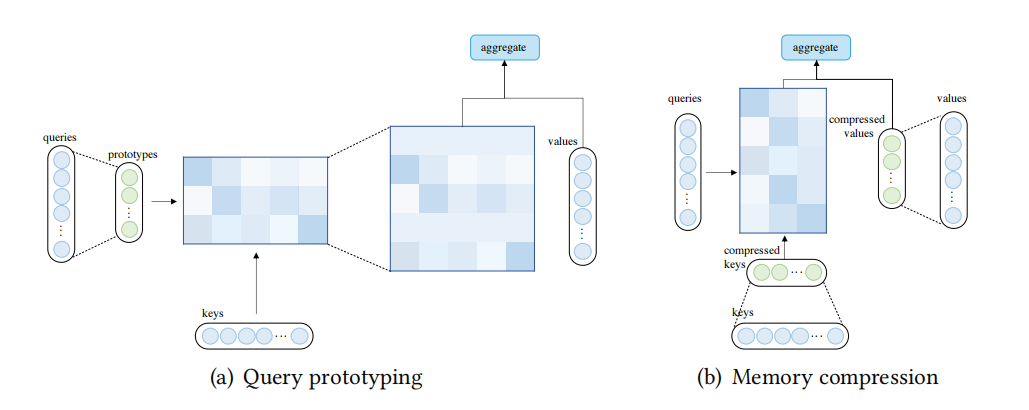
图8:查询原型和键值内存压缩
使用原型查询的注意力机制:在查询原型中,几个查询的原型作为计算注意力分布的主要来源。该模型或者将这些注意力分布复制到所代表的查询的位置上,或者使用离散的均匀分布来填充这些位置。例如clustered attention将查询分为几个集群,然后计算集群中心点的注意力分布,一个集群中的所有查询都共享相应中心点计算的注意力分布;Informer使用明确的查询稀疏度测量法从查询中选择原型,然后,在查询稀疏度测量下,只计算top-u查询的注意力分布,其他查询被分配为离散的均匀分布。
压缩键值内存的注意力机制:可以通过在应用注意力机制之前减少键值对的数量来降低复杂度。例如,Liu等人提出了使用分层卷积的方法减少键和值的数量;Set Transformer和Luna使用一些外部可训练的全局节点总结来自输入的信息,然后将总结后的表征作为输入注意的压缩键值内存。
低秩自注意
一些经验和理论分析报告称,自注意矩阵通常是低秩的,这个属性的含义是双重的,一是低秩属性可以用参数化来显式建模,二是可以用低秩近似值代替自注意力矩阵。
带有先验的注意力
传统意义上,注意力分布是由输入产生的,作为一种广义的情况,注意力分布也可以来自其他来源,我们称之为先验,先验注意力分布可以是对输入产生的分布的补充或替代,我们把这种注意力的表述抽象为带有先验的注意力。在大多数情况下,两种注意力分布的融合可以通过计算对应于先验注意力分布和输入产生的注意力分布的加权和来完成,然后再应用softmax。带有先验的注意力如下图所示,
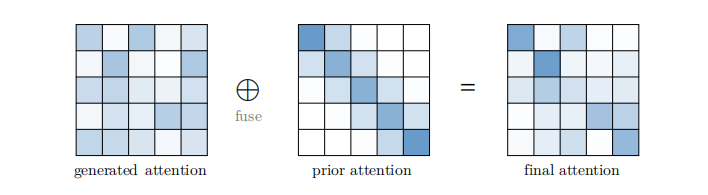
图9:带有先验的注意力
模型位置先验:一些类型的数据(如文本)可以表现出对位置性的强烈偏好,这个属性可以显式编码为先验注意力。一个简单的方法是在位置上使用一个高斯分布,具体来说,我们可以将输入生成的注意力分布与一些高斯密度相乘,然后重新规范化,这相当于在生成的注意力分数中加入偏置项。
底层模块先验:在transformer架构中,经常观察到相邻层的注意力分布相似,因此,很自然地将前一层的注意力分布作为下一层注意力计算的先验。例如,Predictive Attention Transformer提出将二维卷积层应用于以前的注意力分数,并将最终的注意力分数计算为输入生成的注意力分数和卷积分数的凸组合。
多任务适配器先验:适配器是依赖于任务的训练模块,它们附加在预训练网络的特定位置,用于跨任务高效参数共享。
仅注意力先验:一些工作探索了使用独立于输入之间成对交互的注意力分布,换句话说,他们的模型只利用了先验注意力分布。例如,You等人利用高斯分布作为注意力计算的硬编码注意力分布,完全放弃了输入生成的注意力,只使用高斯分布来计算注意力,在这种方法中,均值和方差被设计为超参数,实验表明,硬编码的注意力,当只应用于自注意力时,可以在机器翻译任务中取得与基线模型相当的性能。
改进的多头机制
多头注意能够在不同的位置共同注意来自不同表征子空间的信息,然而,没有任何机制可以保证不同的注意头确实捕捉到不同的特征。
头部行为建模:一系列工作致力于通过引入更复杂的机制来改进多头机制,以指导不同注意力头的行为或允许注意力头之间的互动。例如,Li等人在损失函数中引入了一个辅助的分歧正则化项,以鼓励不同注意力头之间的多样性,两个正则化项分别用于最大化输入子空间和输出表征的余弦距离,而另一个正则化项则是通过相应注意力矩阵的逐元相乘来分散多个头所关注的位置。
跨度受限的多头:原版注意力采用完全注意力跨度假设,其中查询可以关注所有键值对,然而,经常观察到,一些头主要将注意力集中在局部环境中,而其他一些头则关注更广泛的环境,因此,限制注意力的跨度可能是有益的。限制注意力跨度可以表示为将每个注意力分布值与一个掩码值相乘,然后重新归一,传统的注意力为所有距离分配掩码值1。Sukhbaatar采取一个可学习的注意力跨度,即适用一个可学习的标量\(z\)和一个超参数\(R\)来生成mask进而控制跨度。Multi-Scale Transformer采用了固定的跨度,不同层的不同头使用不同的最大跨度,一般来说,底层网络的最大跨度较小,上层网络的最大跨度较大。三种跨度掩码函数如下图所示,

图10:三种跨度掩码函数
- 精细聚合的多头:在每个注意力头计算其输出表示后,原版多头注意力将这些表示连接起来,然后对连接后的表示应用线性变换以获得最终的输出表示。有研究提出说,这种简单的逐个聚合范式并没有充分利用多头注意力的表现力,而使用更为复杂的聚合更为可取。因此有人提出了使用为胶囊网络设计的路由方法,注意力头的输出首先转化为输入胶囊,然后经过迭代路由过程得到输出胶囊,然后将输出胶囊连接起来作为多头注意力的最终输出。
其他模块级别改进
位置表示
很容易验证卷积和循环网络不是置换等变的。 然而,Transformer 中的自注意力模块和位置前馈层都是置换等变的,这可能在建模时成为一个问题,而不是需要输入结构的集合输入问题。 例如,在对文本序列建模时,单词的顺序很重要,因此在 Transformer 架构中正确编码单词的位置至关重要。 因此,需要额外的机制将位置信息注入到 Transformer 中。 一种常见的设计是首先使用向量表示位置信息,然后将向量作为附加输入注入模型。
绝对位置表示
在传统Transformer中,位置信息被编码为绝对正弦位置编码,在位置编码完毕后,将序列中每个位置的位置编码加入到token的词嵌入中,然后送入Transformer。
另一种表示绝对位置的方法是为每个位置学习一组位置嵌入,与手工制作的位置嵌入相比,学习的嵌入更加灵活,因为位置表示可以通过反向传播适应任务,但是,嵌入的数量被限制在训练前确定的最大序列长度内,这使得这种方法不再是归纳性的,也就是说,不能处理比训练时看到的序列更长的序列。
合并绝对位置表示的基本方法是在token嵌入中添加位置编码。然而,当输入信号在层间传播时,位置信息可能会在上层丢失。后来的工作发现,将位置表示添加到每个Transformer层的输入中是有益的。
相对位置表示
另一系列工作侧重于表示token之间的位置关系,而不是单个token的位置,直觉认为,在自注意力中输入元素(方向和距离)之间的成对位置关系可能比元素的位置更有益。遵循这一原则的方法称为相对位置表示。
其他表示
一些研究已经探索使用包含绝对和相对位置信息的混合位置表示。 Transformer with Untied Position Encoding (TUPE) 将注意力分数的计算重新设计为内容到内容项、绝对位置到位置项和表示相对位置关系的偏置项的组合。
没有显式编码的位置表示
Wang 等人没有明确引入额外的位置编码,建议通过将嵌入推广到位置上的连续(复值)函数来对词嵌入中的位置信息进行编码。
Transformer decoder的位置表示
在解码器的交叉注意中采取了掩码的自注意,而掩码的自注意不是置换等变的,因此,仅利用Transformer解码器的模型具有在不包含显式位置表示的情况下感知位置信息的潜力。语言建模任务的一些实证结果证实了这一点,作者发现删除位置编码甚至可以提高性能。
层归一化
层归一化(LN)和残差连接被认为是一种稳定深度网络训练的机制(例如,缓解不理想的梯度和模型退化的问题),目前已经有一些研究致力于分析和改进LN模块。
LN的放置
在传统Transformer中,LN层位于残差块之间,称为post-LN,后来的Transformer实现将LN层放在注意力或FFN之前的残差连接内,在最后一层之后有一个额外的LN来控制最终的输出大小,这被称为pre-LN,post-LN和pre-LN的架构如下图所示,
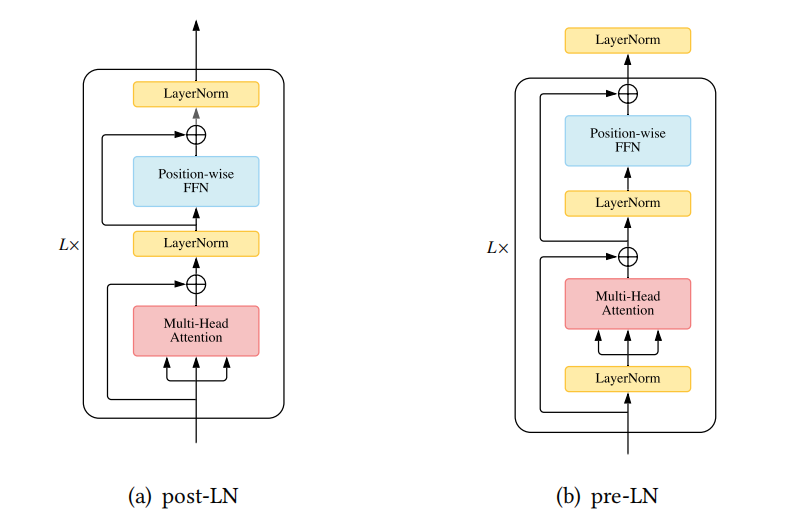
图11:post-LN和pre-LN的架构对比
另外,warm-up阶段可以从pre-LN Transformer上安全地去除,而不必担心输出层附近梯度过大导致训练不稳定的情况。