多模态情感分析综述
多模态情感分析是一个越来越受欢迎的研究领域,它将传统的基于文本的情感分析任务扩展到多模态的情景下,多模态包括文本、视频和语音模态,以往的情感分析任务通常聚焦于单个模态,但在某些情况下,仅仅通过文本模态来分析说话人的情感是不够的,如以下语句
The movie is sick.
这句话本身所要表达的意思是模棱两可的,但如果说话者在说这句话的同时也在微笑,那么它就会被认为是积极的(positive),反过来说,如果说话者在说这句话的同时皱着眉头,则这句话被认为是消极的(negative),以上例子说明了双模态信息之间的互动,其中微笑和皱着眉头等信息能够在视频模态中体现出来。然后我们可以继续加入语音模态从而考虑三模态的情况,当说话声音较大时,这句话的积极情感会进一步增强,但加入使用fair替换掉sick这个单词,虽然同样是大声说话的情景,但考虑到fair这个词的强烈影响,这句话的情感并没有因为大声说话而产生巨大变化。以上例子说明了模态间信息交互的复杂性,但不可置疑的是,视频和语音模态中可能包含文本模态中的互补信息,因此,在多模态场景下进行情感分析任务更具有可信性。
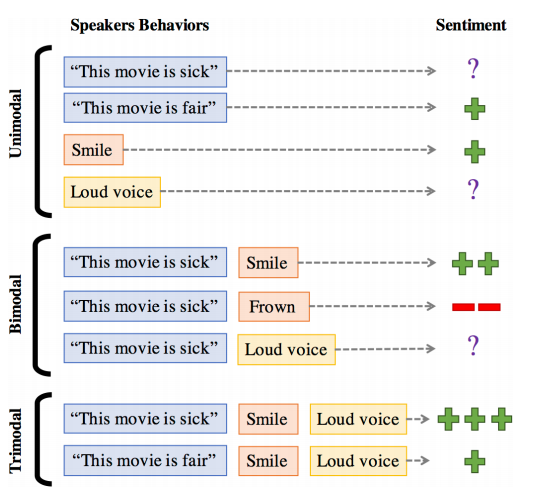
图1:模态之间信息的互动
现阶段的多模态情感分析任务,大多站在如何有效地将多模态的特征信息进行融合这一角度考虑问题,目的是排除与情感分析任务无关的噪声数据,最大化利用与情感分析任务相关的多模态数据,包括单模态内的数据交互与模态间的数据交互,最终达到分析情感极性的目标。本文主要就多模态数据集和多模态特征的融合方法进行介绍。
数据集
多模态特征融合方法
早期融合
早期融合,也被称为特征级别的融合,直接将来自不同模式的特征表示连接成一个单一的表示,这是一种最直观的方法。下图展示了早期融合的具体操作。
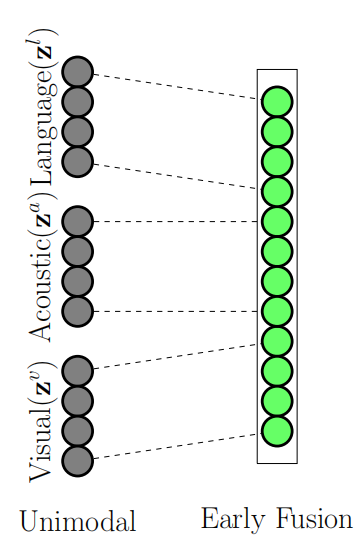
图2:早期融合具体操作
但是,由于来自不同模态的特征表示可能存在巨大差异,我们必须考虑时间同步问题,即不同模态的特征表示必须在时间层面上进行对齐,以便在融合前将这些特征表示转化为相同的格式,所以在某一个模态或某几个模态有信息缺失的情况下,早期融合的方法不能对模态间的互动进行有效建模。 另外,因为早期融合直接将不同模态的特征表示进行连接,可能会造成融合特征表示较为复杂的情况,最终会导致过拟合的发生。
后期融合
后期融合,也被称为决策级别的融合,通常是整合来自每一个单一模态的预测结果,即首先利用每一个模态的数据信息进行预测,再将每一个模态的预测结果进行整合,流行的整合方法包括平均法、投票法和信号差异法。
后期融合的优点包括:
- 灵活性,可以为每个模态的数据选择最佳的分类器。
- 鲁棒性,当某些模态的数据有缺失时,后期融合的方法依然可以工作。
但是后期融合的方法也有相当大的缺点,即不能够有效学习模态间的信息交互,不同模态数据之间的相关性和差异性被忽略。
基于张量的融合
基于张量的融合方法建立了一个融合层,具体融合方法为在三维向量场中将每种模态的向量表示进行外积操作得到融合向量表示,操作方法如图所示,
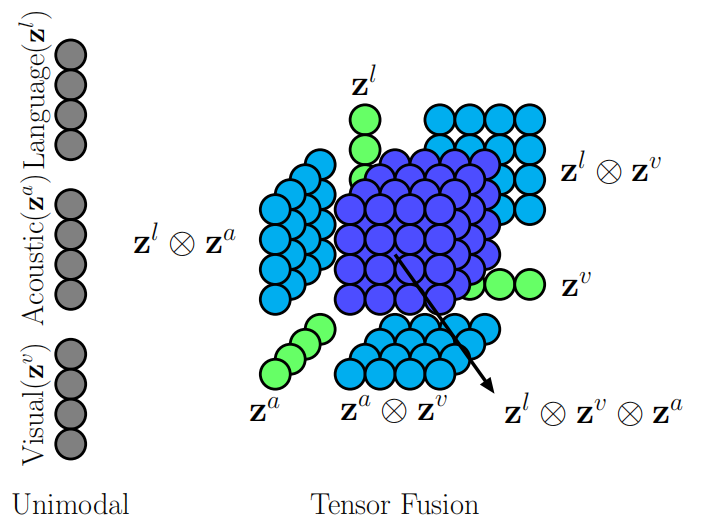
图3:基于张量的融合方法
需要注意的是,不同模态的特征在进行融合时还需要保留原模态的特征,这样可以更好地利用单模态内的信息,基于张量的融合方法也考虑到这一点,在每一个模态的向量末尾连接1,这样在进行外积的同时还能够保留原有模态的特征,下图以视频模态和文本模态的特征融合为例说明了这一点,
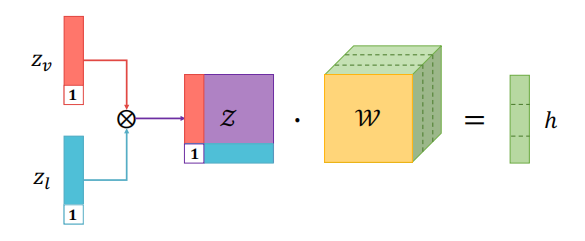
图4:视频模态和文本模态的特征融合
可以使用如下公式来表示文本模态、语音模态和视频模态的融合过程,其中\(\mathbf{z}^{m}\)表示融合特征向量,\(\mathbf{z}^{l}\)表示文本模态特征向量,\(\mathbf{z}^{v}\)表示视频模态特征向量,\(\mathbf{z}^{a}\)表示语音模态特征向量,可以结合图4来理解以下公式,其中\(\mathbf{z}^{l} \otimes \mathbf{z}^{v}\)、\(\mathbf{z}^{a} \otimes \mathbf{z}^{v}\)和\(\mathbf{z}^{l} \otimes \mathbf{z}^{a}\)表示双模态之间的信息互动,\(\mathbf{z}^{l} \otimes \mathbf{z}^{v} \otimes \mathbf{z}^{a}\)表示三模态之间的信息互动。
\[ \mathbf{z}^{m}=\left[\begin{array}{c} \mathbf{z}^{l} \\ 1 \end{array}\right] \otimes\left[\begin{array}{c} \mathbf{z}^{v} \\ 1 \end{array}\right] \otimes\left[\begin{array}{c} \mathbf{z}^{a} \\ 1 \end{array}\right] \]
基于张量的融合方法显式地建模了单模态、双模态、三模态之间的信息互动,并且虽然融合特征向量是高维向量,但由于单模态特征之间是通过外积操作来进行融合的,没有可学习的参数,所以不用考虑过拟合的问题。
低秩多模态融合方法
以上我们已经介绍了基于张量的融合方法,但这种方法往往会因为将单模态向量转化为融合张量而导致维度和计算复杂性的指数级增长(外积操作所致),为了解决基于张量的多模态融合方法计算效率差的问题,提出了一种低秩多模态融合的方法,主要是利用了将张量和权重并行分解的思想。
首先我们需要明确输出\(h\)的计算方法,如以下公式所示,
\[ h=g(\mathcal{Z} ; \mathcal{W}, b)=\mathcal{W} \cdot \mathcal{Z}+b, h, b \in \mathbb{R}^{d_{y}} \]
其中\(\mathcal{Z}\)为融合张量,低秩多模态融合方法首先将权重\(\mathcal{W}\)进行分解为如下形式,
\[ \mathcal{W}=\sum_{i=1}^{r} \bigotimes_{m=1}^{M} \mathbf{w}_{m}^{(i)} \]
可以首先尝试理解一下作者这样分解的目的,即为了利用类似于分配律的原理让外积操作变为对应元素的乘积,最终达到每种模态数据乘以对应权重,然后再进行element wise(对应元素乘积)的操作的目标,以下我们可以尝试证明一下,
\[ \begin{aligned} h &=\left(\sum_{i=1}^{r} \bigotimes_{m=1}^{M} \mathbf{w}_{m}^{(i)}\right) \cdot \mathcal{Z} \\ &=\sum_{i=1}^{r}\left(\bigotimes_{m=1}^{M} \mathbf{w}_{m}^{(i)} \cdot \mathcal{Z}\right) \\ &=\sum_{i=1}^{r}\left(\bigotimes_{m=1}^{M} \mathbf{w}_{m}^{(i)} \cdot \bigotimes_{m=1}^{M} z_{m}\right) \\ &=\Lambda_{m=1}^{M}\left[\sum_{i=1}^{r} \mathbf{w}_{m}^{(i)} \cdot z_{m}\right] \end{aligned} \]
其中公式中的\(\Lambda\)符号表示对应元素乘积的操作,特别地,有以下记法:\(\Lambda_{t=1}^{3} x_{t}=x_{1} \circ x_{2} \circ x_{3}\),最终可以使用下图来表示低秩多模态融合方法,
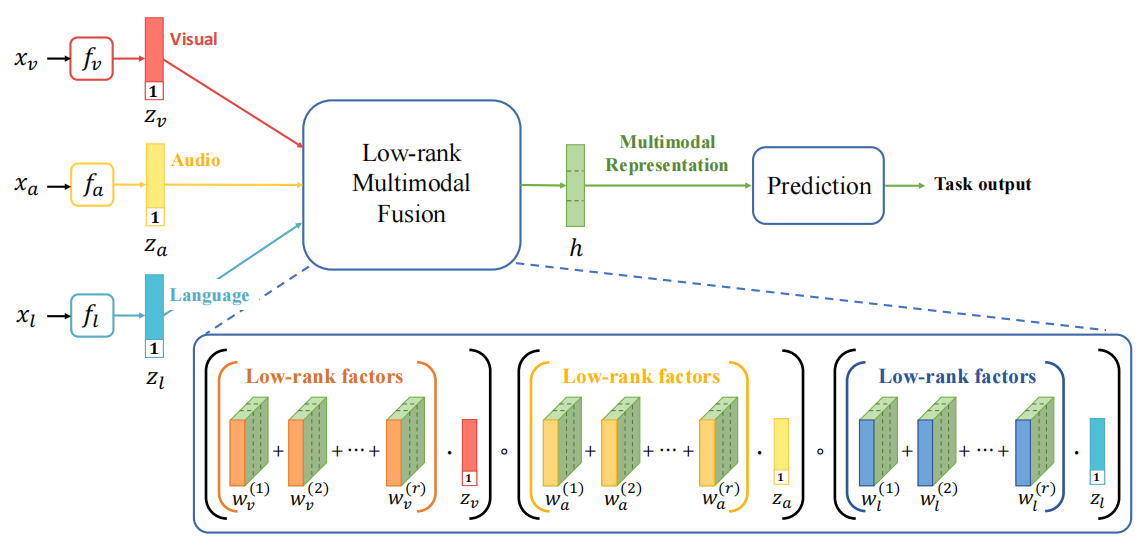
图5:低秩多模态融合方法
基于神经网络的融合方法
基于神经网络的融合采用了一种直接和直观的策略,通过神经网络融合不同模态的特征表示。基于注意力的融合使用注意力机制来获得一组具有标量权重的特征表示的加权和,这些标量权重是由一个注意力模块动态学习的。还有一些融合方法参考了当前比较流行的Transformer和BERT结构的思想,这些使用深度模型的融合方法能够以端到端的方式从大量的数据中学习,具有良好的性能,但也存在可解释性低的问题。
基于注意力机制的融合方法
注意力机制被用于多模态融合是很容易想到的操作,注意力机制天然地能够发掘源模态和目标模态的联系,从而生成注意力权重,通过乘积进一步加强目标模态的特征表示,注意力机制很适用于发掘模态之间的共同特征,但对于发掘模态的特有特征就显得有些力不从心。这里我们以记忆融合网络(MFN)为例来探索注意力机制在多模态融合方面的应用。
注意力机制通常不会单独应用在多模态特征融合中,可能还会结合其他结构,如MFN由三个主要部分组成,分别是LSTM系统、Delta-Memory注意力网络、多模态门控记忆,其中LSTM系统有多个长短期记忆网络(LSTM)组成,每个模态对应一个LSTM网络,LSTM对模态内的信息的交互进行建模,或者说对每个时间步的模态信息进行记忆;Delta-Memory注意力网络是一种特殊的注意力机制,旨在发现LSTM系统中不同模态记忆间的横向交互关系;多模态门控记忆结构是一种统一的记忆存储,存储随着时间步推移的跨模态信息交互,总结下来,LSTM结构致力于模态内信息的建模,Delta-Memory注意力网络和多模态门控记忆结构致力于模态间信息的建模,模型总体结构如下所示,
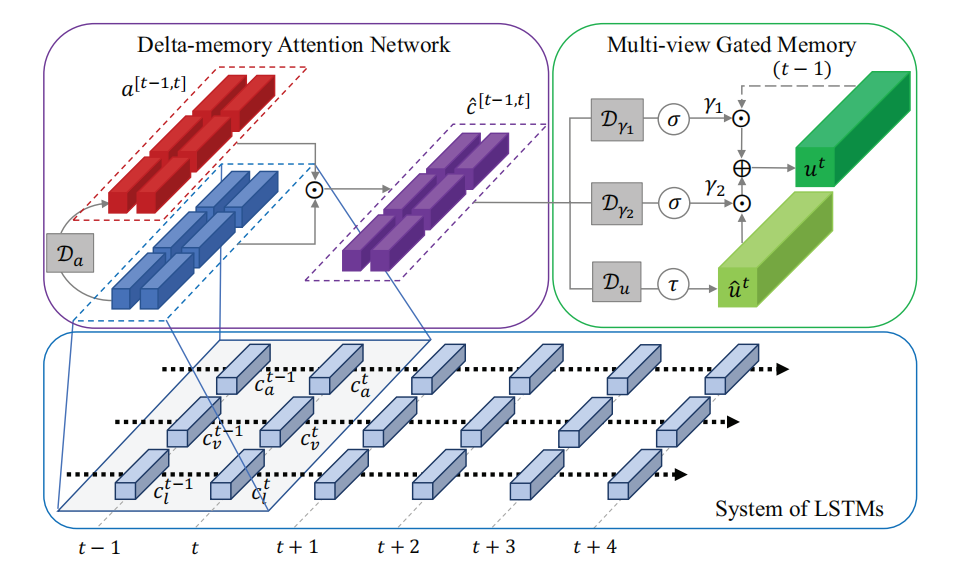
图6:记忆融合网络(MFN)的整体架构
Delta-Memory注意力网络截取\(t-1\)和\(t\)两个时间步的LSTM系统输出信息,目的是为了防止重复的跨模态交互信息被赋高权重的情况,如果有了两个时间步的模态信息之后,就可以将两个时间步的信息进行比较从而将高系数分配给那些将要变化的模态信息,文中指出,理想情况下,在LSTM系统的记忆状态发生变化之前,每个跨模态交互只分配一次高系数。Delta-Memory注意力网络中的计算公式如下所示,首先计算出注意力权重系数,再将系数乘以原模态特征表示。
\[ \begin{gather*} a^{[t-1, t]}=\mathcal{D}_{a}\left(c^{[t-1, t]}\right) \\ \hat{c}^{[t-1, t]}=c^{[t-1, t]} \odot a^{[t-1, t]} \end{gather*} \]
多模态门控记忆结构存储了一段时间内跨模态信息交互的历史,包括两个门,分别是保持门和更新门,其中保持门分配上一个时间步的记忆,更新门根据更新建议(或称为当前时间步状态)来进行更新,计算公式如下所示,
\[ \begin{gather*} \hat{u}^{t}=\mathcal{D}_{u}\left(\hat{c}^{[t-1, t]}\right) \\ \gamma_{1}^{t}=\mathcal{D}_{\gamma_{1}}\left(\hat{c}^{[t-1, t]}\right), \gamma_{2}^{t}=\mathcal{D}_{\gamma_{2}}\left(\hat{c}^{[t-1, t]}\right) \\ u^{t}=\gamma_{1}^{t} \odot u^{t-1}+\gamma_{2}^{t} \odot \tanh \left(\hat{u}^{t}\right) \end{gather*} \]
多模态Transformer融合方法
这里介绍的多模态Transformer融合方法出自Multimodal Transformer for Unaligned Multimodal Language Sequences一文,文章提出了MulT结构,主要应用于非对齐多模态语言序列场景。相关研究表明,在对多模态的语言时间序列数据进行建模时主要存在两个挑战:
- 由于每种模态序列的采样率不同,导致数据没有在时间层面上对齐。
- 不同模态的元素之间存在长距离依赖的现象。
文章中提出的MulT结构以端到端的方法解决了上述问题。MulT结构以跨模态的Transformer作为主要结构来建模模态与模态(双模态)之间的关系,具体来说,每个跨模态Transformer通过学习两个模态之间的注意力,用另一个源模态的低级特征反复强化目标模态,以视频模态和文本模态为例,第一种情况下,以视频模态为源模态,以文本模态为目标模态,在每一个跨模态的注意力机制块中,将源模态特征向量作为注意力机制的\(Q\),将目标模态特征向量作为注意力机制的\(K\)、\(V\),经过注意力机制计算得到注意力权重,将权重乘以目标模态特征向量得到强化后的目标模态特征向量,计算公式如下所示,
\[ \text { Attention }(\mathrm{Q}, \mathrm{K}, \mathrm{V})=\operatorname{softmax}\left(\frac{\mathrm{QK}^{\mathrm{T}}}{\sqrt{\mathrm{d}_{\mathrm{k}}}}\right) \mathrm{V} \]
实际情况下采用的多为多头注意力机制;第二种情况下,以文本模态为源模态,以视频模态为目标模态,其他计算过程相同。跨模态的注意力机制块的堆叠组成了跨模态的Transformer结构,另外,这里只着重强调了跨模态的注意力机制块中的跨模态的注意力机制计算细节,跨模态的注意力机制块除了交叉注意力结构,还包括前馈神经网络等结构。跨模态的注意力机制块结构如下所示,
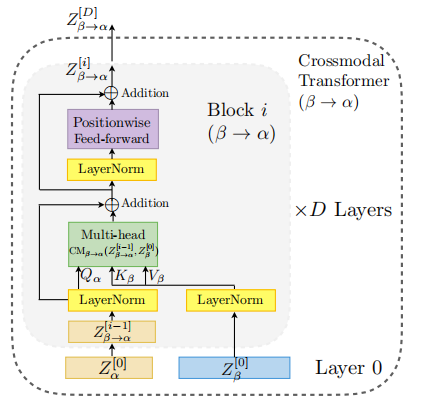
图7:跨模态注意力机制块结构
MulT的整体架构如下图所示,在这里我们只关注模态信息融合的部分,即架构的中间部分,可以从图中看到,在完成特征向量的处理之后,将两个模态的特征向量分别作为源模态和目标模态输入到跨模态的Transformer结构中,两个Transformer的输出进行连接,再输入到Transformer结构中,不同的是,跨模态的Transformer中进行的主要是交叉注意力计算,而上部的Transformer中进行的主要是自注意计算。架构的底部和顶部在这里不作主要关注,只需要明确架构的底部为特征向量的处理,架构的顶部为下游任务的适应。
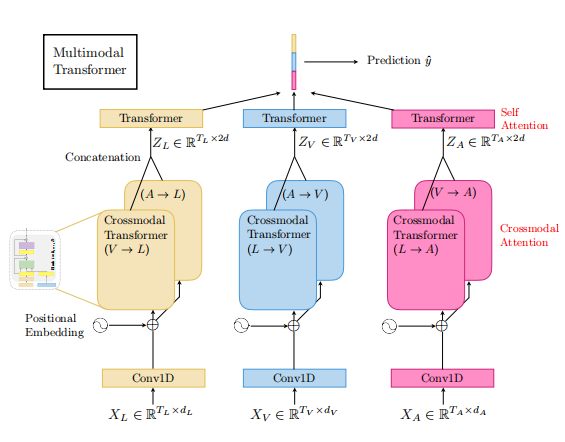
图8:MulT的整体架构
基于神经网络的融合方法在可解释性方面的改进
一般的基于神经网络的融合方法在可解释性方面都表现较差,所以出现了一些提高可解释性的尝试,现有大多数的尝试是在挖掘共同和独特信息方面的改进。一些框架可以从多模态特征表示中提取公共信息,同时获取一些独特信息,这里的独特信息通常是指特定于模态的信息,最后再通过融合层将共同信息和独特信息进行整合。
将DeepCU结构作为示例进行说明,DeepCU包括两个子网络,包括可以获取模态特性的独特子网络,以及由深度卷积张量网络组成的共同子网络。DeepCU可以通过两个子网络获取到互补的信息,进而通过融合层进行信息整合。DeepCU框架示意图如下所示,
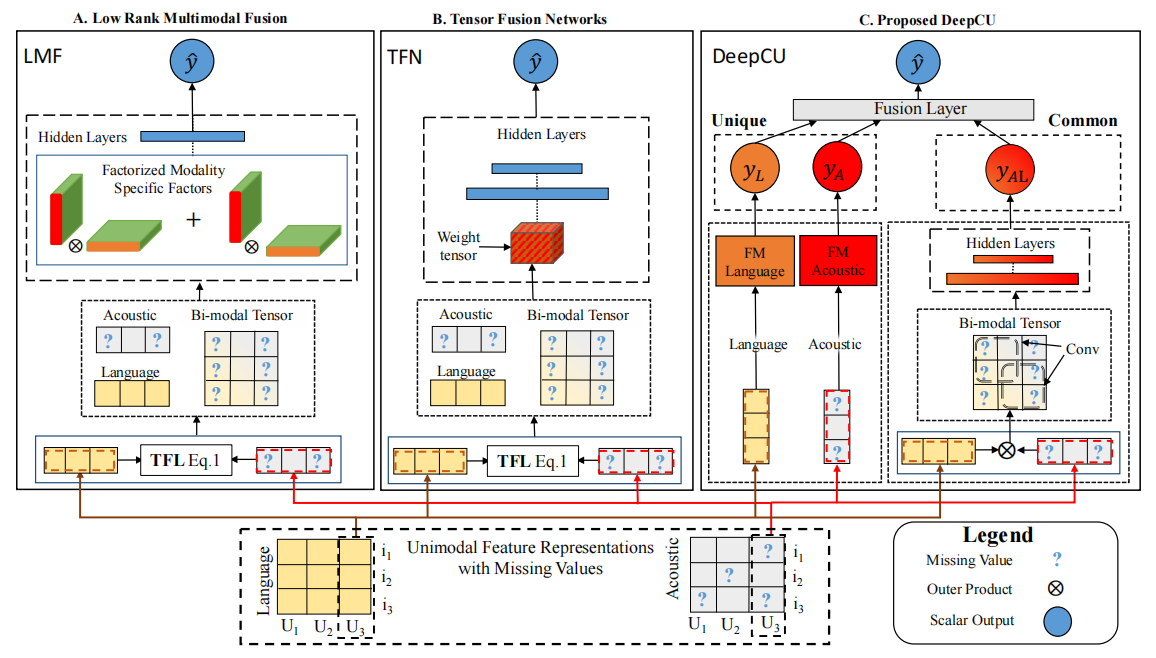
图9:DeepCU的整体架构
框架示意图左边是TFN和LMF架构的示意图,DeepCU相较于TFN和LMF更具表现力,因为它在共同子网络中捕获了非线性的多模态交互关系,在独特子网络中不会了分解的非线性特征关系,缓解了缺失值场景,增强了模型的泛化能力。
首先介绍独特子网络获得特定于模态信息的方法,从三个模态提取潜在特征之后,为了能对单模态中信息与信息的交互进行建模,这里采取的是分解机的方法,采用分解机的另一个好处是可以缓解缺失值场景,分解机公式如下所示,
\[ \hat{y}_{F M(\boldsymbol{x})}=w_{0}+\sum_{i=1}^{n} \boldsymbol{w}_{i} \boldsymbol{x}_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n} \boldsymbol{v}_{i}^{T} \boldsymbol{v}_{j} \cdot \boldsymbol{x}_{i} \boldsymbol{x}_{j} \]
然后我们对共同子网络进行介绍。共同子网络首先将三个模态的潜在特征进行外积,得到联合表示张量,类似于TFN的做法,其中张量的每个元素代表融合模态元素之间的相互作用强度,然后我们在这些张量上运用卷积操作,因为卷积核是非线性的特征提取器,所以比前馈层的泛化效果更好,并且能够有效降低复杂度,最后再将卷积操作输出输入到全连接层中。融合层的操作较为简单,只采取了简单的连接和转置操作。
上文提到过尝试挖掘共同和独特信息方面的改进,介绍了在挖掘模态共同和独特信息方面的方法,但是挖掘独特信息并不一定指模态独特信息,Deep-HOSeq架构的独特子网络挖掘的是时间步上的独特信息,旨在发现时间与语义观点上的协作,以下是Deep-HOSeq整体架构示意图,
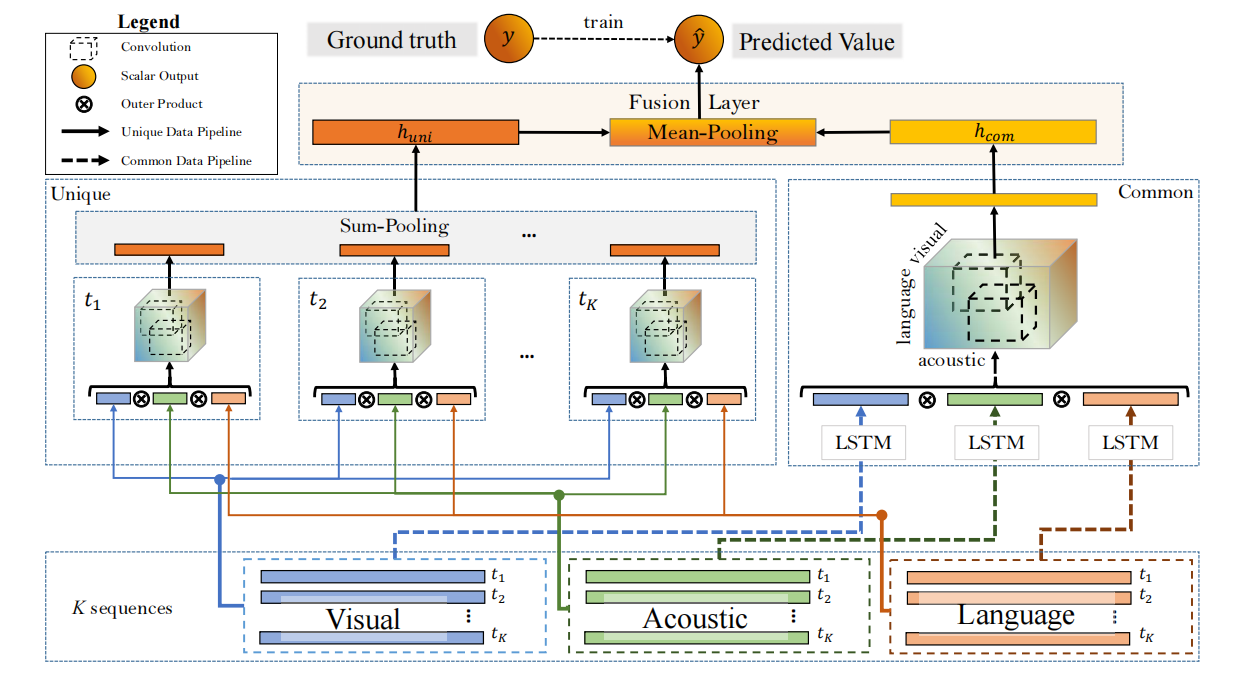
图10:Deep-HOSeq的整体架构
Deep-HOSeq处理独特子网络的方法是,将每个时间步的各个模态的向量进行外积操作,再进行卷积操作,得到每个时间步的独特信息,经过sum-pooling进行相加,得到独特向量。Deep-HOSeq处理共同子网络和DeepCU处理共同子网络的方法类似。